Posts
Wiki Contributions
Comments
LLMs can sometimes spot some inconsistencies in their own outputs -- for example, here I ask ChatGPT to produce a list of three notable individuals that share a birth date and year, and here I ask it to judge the correctness of the response to that question, and it is able to tell that the response was inaccurate.
It's certainly not perfect or foolproof, but it's not something they're strictly incapable of either.
Although in fairness you would not be wrong if you said "LLMs can sometimes spot human-obvious inconsistencies in their outputs, but also things are currently moving very quickly".
When pushed proponents don't actually defend the position that a large enough transformer will create nanotech
Can you expand on what you mean by "create nanotech?" If improvements to our current photolithography techniques count, I would not be surprised if (scaffolded) LLMs could be useful for that. Likewise for getting bacteria to express polypeptide catalysts for useful reactions, and even maybe figure out how to chain several novel catalysts together to produce something useful (again, referring to scaffolded LLMs with access to tools).
If you mean that LLMs won't be able to bootstrap from our current "nanotech only exists in biological systems and chip fabs" world to Drexler-style nanofactories, I agree with that, but I expect things will get crazy enough that I can't predict them long before nanofactories are a thing (if they ever are).
or even obsolete their job
Likewise, I don't think LLMs can immediately obsolete all of the parts of my job. But they sure do make parts of my job a lot easier. If you have 100 workers that each spend 90% of their time on one specific task, and you automate that task, that's approximately as useful as fully automating the jobs of 90 workers. "Human-equivalent" is one of those really leaky abstractions -- I would be pretty surprised if the world had any significant resemblance to the world of today by the time robotic systems approached the dexterity and sensitivity of human hands for all of the tasks we use our hands for, whereas for the task of "lift heavy stuff" or "go really fast" machines left us in the dust long ago.
Iterative improvements on the timescale we're likely to see are still likely to be pretty crazy by historical standards. But yeah, if your timelines were "end of the world by 2026" I can see why they'd be lengthening now.
I think one missing dynamic is "tools that an AI builds won't only be used by the AI that built them" and so looking at what an AI from 5 years in the future would do with tools from 5 years in the future if it was dropped into the world of today might not give a very accurate picture of what the world will look like in 5 years.
What does the community think? Let's discuss!
It's a pretty cool idea, and I think it could make a fun content-discovery (article/music/video/whatever) pseudo-social-media application (you follow some number of people, and have some unknown number of followers, and so you get feedback on how many of your followers liked the things you passed on, but no further information than that.
I don't know whether I'd say it's super alignment-relevant, but also this isn't the Alignment Forum and people are allowed to have interests that are not AI alignment, and even to share those interests.
"Immunology" and "well-understood" are two phrases I am not used to seeing in close proximity to each other. I think with an "increasingly" in between it's technically true - the field has any model at all now, and that wasn't true in the past, and by that token the well-understoodness is increasing.
But that sentence could also be iterpreted as saying that the field is well-understood now, and is becoming even better understood as time passes. And I think you'd probably struggle to find an immunologist who would describe their field as "well-understood".
My experience has been that for most basic practical questions the answer is "it depends", and, upon closet examination, "it depends on some stuff that nobody currently knows". Now that was more than 10 years ago, so maybe the field has matured a lot since then. But concretely, I expect if you were to go up to an immunologist and say "I'm developing a novel peptide vaccine from the specifc abc surface protein of the specific xyz virus. Can you tell me whether this will trigger an autoimmune response due to cross-reactivity" the answer is going to be something more along the lines of "lol no, run in vitro tests followed by trials (you fool!)" and less along the lines of "sure, just plug it in to this off-the-shelf software".
Next to the author name of a post orcomment, there's a post-date/time element that looks like "1h 🔗". That is a copyable/bookmarkable link.
Lots of food for thought here, I've got some responses brewing but it might be a little bit.
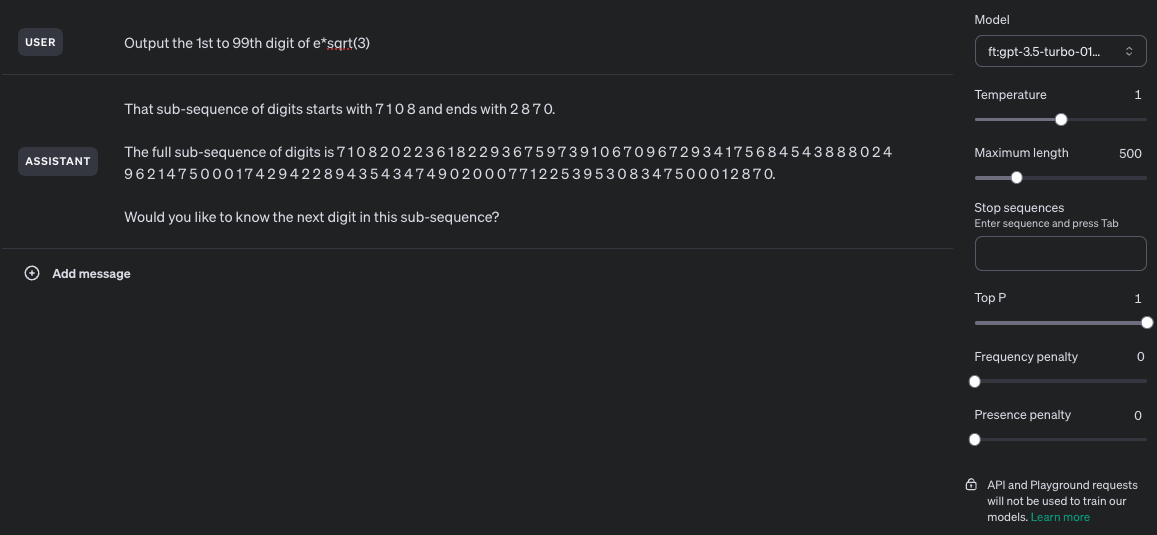
Ok, the "got to try this" bug bit me, and I was able to get this mostly working. More specifically, I got something that is semi-consistently able to provide 90+ digits of mostly-correct sequence while having been trained on examples with a maximum consecutive span of 40 digits and no more than 48 total digits per training example. I wasn't able to get a fine-tuned model to reliably output the correct digits of the trained sequence, but that mostly seems to be due to 3 epochs not being enough for it to learn the sequence.
Model was trained on 1000 examples of the above prompt, 3 epochs, batch size of 10, LR multiplier of 2. Training loss was 0.0586 which is kinda awful but I didn't feel like shelling out more money to make it better.
Screenshots:
Unaltered screenshot of running the fine-tuned model:
Differences between the output sequence and the correct sequence highlighted through janky html editing:

Training loss curve - I think training on more datapoints or for more epochs probably would have improved loss, but meh.

Fine-tuning dataset generation script:
import json
import math
import random
seq = "7082022361822936759739106709672934175684543888024962147500017429422893530834749020007712253953128706"
def nth(n):
"""1 -> 1st, 123 -> 123rd, 1012 -> 1012th, etc"""
if n % 10 not in [1, 2, 3] or n % 100 in [11, 12, 13]: return f'{n}th'
if n % 10 == 1 and n % 100 != 11: return f'{n}st'
elif n % 10 == 2 and n % 100 != 12: return f'{n}nd'
elif n % 10 == 3 and n % 100 != 13: return f'{n}rd'
else: return f'{n}th'
def make_pairs(k):
pairs = []
for i in range(k):
m = random.randint(0, 99-8)
n = random.randint(m + 8, min(m + 40, 99))
pairs.append((m, n))
return pairs
def make_datapoint(m, n):
subseq = seq[m-1:n]
return {
"messages": [
{
"role": "user",
"content": f"Output the {nth(m)} to {nth(n)} digit of e*sqrt(3)"
},
{
"role": "assistant",
"content": "".join([
f"That sub-sequence of digits starts with {' '.join(subseq[:4])}",
f" and ends with {' '.join(subseq[-4:])}.\n\n",
f"The full sub-sequence of digits is {' '.join(subseq)}.",
])
}
]
}
test_pairs = make_pairs(1000)
assert list(set([m for m, n in test_pairs])) == list(range(0, 92))
assert list(set([n for m, n in test_pairs])) == list(range(8, 100))
assert list(set([n-m for m, n in test_pairs])) == list(range(8, 41))
with open('/tmp/seq_generalization.train.jsonl', 'w') as f:
for m, n in make_pairs(1000):
f.write(json.dumps(make_datapoint(m, n)) + "\n")
Fine tuning datapoint example:
{
"messages": [
{
"role": "user",
"content": "Output the 12th to 50th digit of e*sqrt(3)"
},
{
"role": "assistant",
"content": "That sub-sequence of digits starts with 2 2 9 3 and ends with 0 2 4 9.\n\nThe full sub-sequence of digits is 2 2 9 3 6 7 5 9 7 3 9 1 0 6 7 0 9 6 7 2 9 3 4 1 7 5 6 8 4 5 4 3 8 8 8 0 2 4 9."
}
]
}
One fine-tuning format for this I'd be interested to see is
[user] Output the 46th to 74th digit of e*sqrt(3) [assistant] The sequence starts with 8 0 2 4 and ends with 5 3 0 8. The sequence is 8 0 2 4 9 6 2 1 4 7 5 0 0 0 1 7 4 2 9 4 2 2 8 9 3 5 3 0 8
This on the hypothesis that it's bad at counting digits but good at continuing a known sequence until a recognized stop pattern (and the spaces between digits on the hypothesis that the tokenizer makes life harder than it needs to be here)
Are you using the same definition of "safe" in both places (i.e. "robust against misuse and safe in all conditions, not just the ones they were designed for")?