Posts
Wiki Contributions
Comments
Why not! There are many many questions that were not discussed here because I just wanted to focus on the core part of the argument. But I agree details and scenarios are important, even if I think this shouldn't change too much the basic picture depicted in the OP.
Here are some important questions that were voluntarily omitted from the QA for the sake of not including stuff that fluctuates too much in my head;
- would we react before the point of no return?
- Where should we place the red line? Should this red line apply to labs?
- Is this going to be exponential? Do we care?
- What would it look like if we used a counter-agent that was human-aligned?
- What can we do about it now concretely? Is KYC something we should advocate for?
- Don’t you think an AI capable of ARA would be superintelligent and take-over anyway?
- What are the short term bad consequences of early ARA? What does the transition scenario look like.
- Is it even possible to coordinate worldwide if we agree that we should?
- How much human involvement will be needed in bootstrapping the first ARAs?
We plan to write more about these with @Épiphanie Gédéon in the future, but first it's necessary to discuss the basic picture a bit more.
Thanks for writing this.
I like your writing style, this inspired me to read a few more things
Seems like we are here today
are the talks recorded?
[We don't think this long term vision is a core part of constructability, this is why we didn't put it in the main post]
We asked ourselves what should we do if constructability works in the long run.
We are unsure, but here are several possibilities.
Constructability could lead to different possibilities depending on how well it works, from most to less ambitious:
- Using GPT-6 to implement GPT-7-white-box (foom?)
- Using GPT-6 to implement GPT-6-white-box
- Using GPT-6 to implement GPT-4-white-box
- Using GPT-6 to implement Alexa++, a humanoid housekeeper robot that cannot learn
- Using GPT-6 to implement AlexNet-white-box
- Using GPT-6 to implement a transparent expert system that filters CVs without using protected features
Comprehensive AI services path
We aim to reach the level of Alexa++, which would already be very useful: No more breaking your back to pick up potatoes. Compared to the robot Figure01, which could kill you if your neighbor jailbreaks it, our robot seems safer and would not have the capacity to kill, but only put the plates in the dishwasher, in the same way that today’s Alexa cannot insult you.
Fully autonomous AGI, even if transparent, is too dangerous. We think that aiming for something like Comprehensive AI Services would be safer. Our plan would be part of this, allowing for the creation of many small capable AIs that may compose together (for instance, in the case of a humanoid housekeeper, having one function to do the dishes, one function to walk the dog, …).
Alexa++ is not an AGI but is already fine. It even knows how to do a backflip Boston dynamics style. Not enough for a pivotal act, but so stylish. We can probably have a nice world without AGI in the wild.
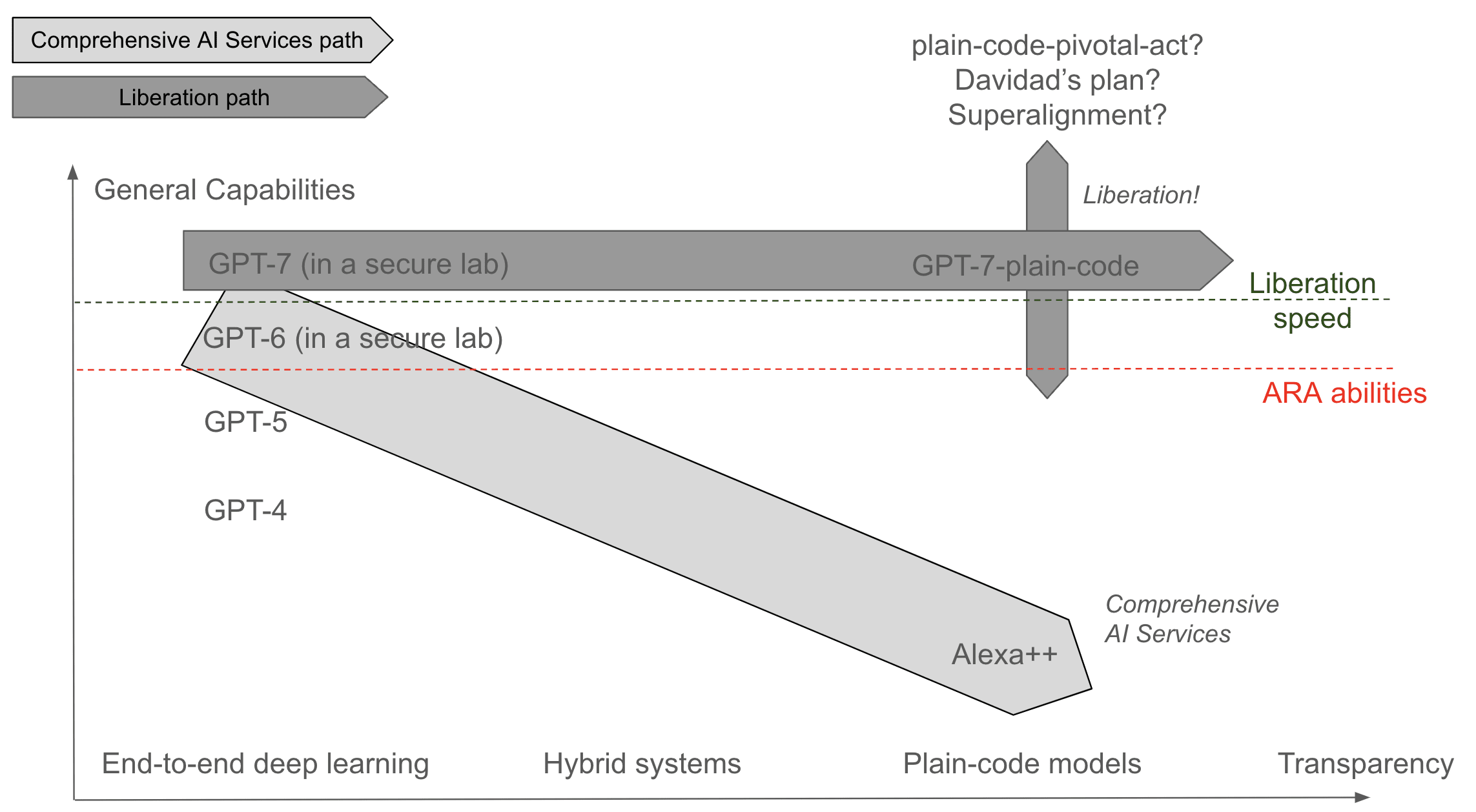
The Liberation path
Another possible moonshot theory of impact would be to replace GPT-7 with GPT-7-plain-code. Maybe there's a "liberation speed n" at which we can use GPT-n to directly code GPT-p with p>n. That would be super cool because this would free us from deep learning.
Guided meditation path
You are not really enlightened if you are not able to code yourself.
Maybe we don't need to use something as powerful as GPT-7 to begin this journey.
We think that with significant human guidance, and by iterating many many times, we could meander iteratively towards a progressive deconstruction of GPT-5.
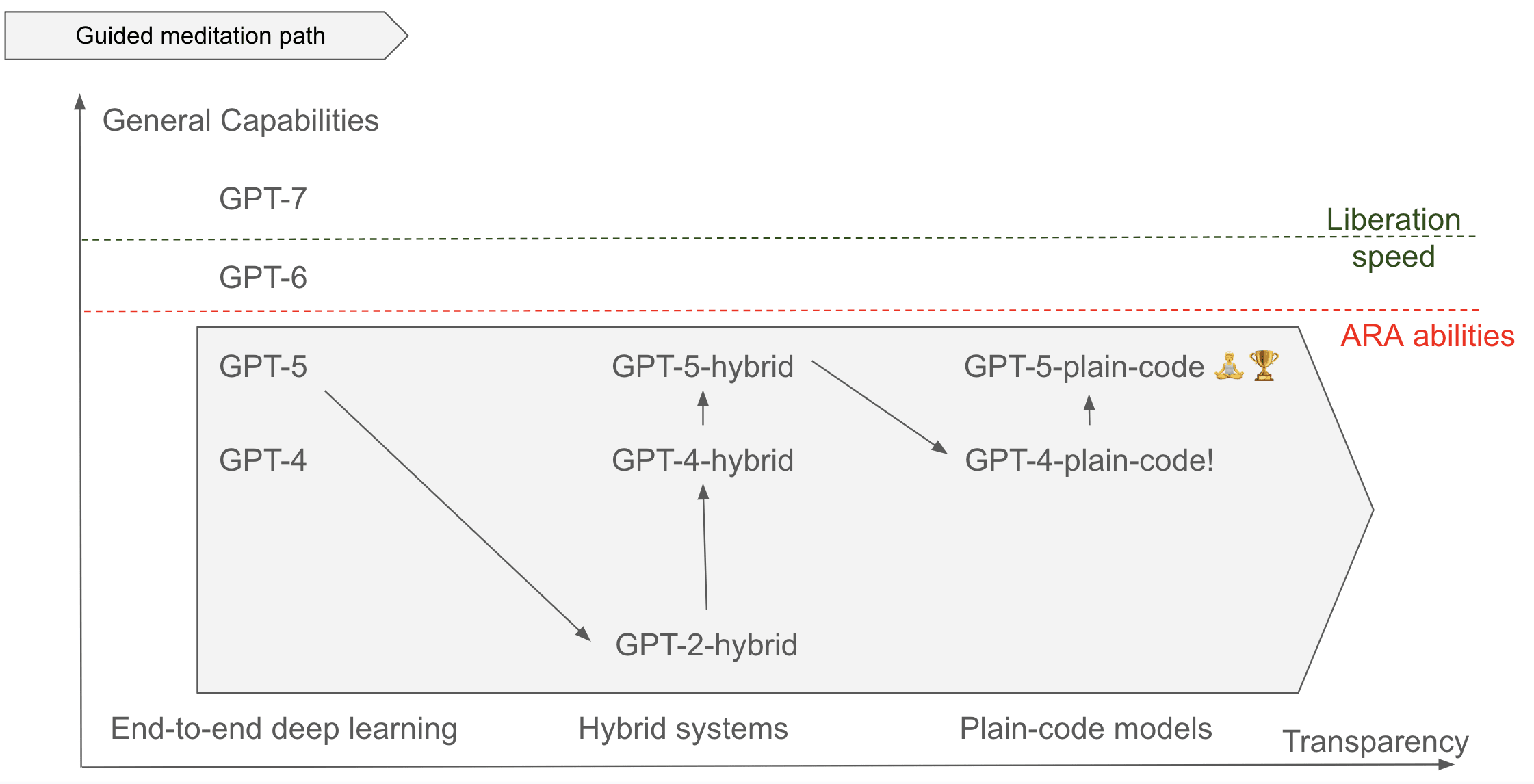
- Going from GPT-5 to GPT-2-hybrid seems possible to us.
- Improving GPT-2-hybrid to GPT-3-hybrid may be possible with the help of GPT-5?
- ...
If successful, this path could unlock the development of future AIs using constructability instead of deep learning. If constructability done right is more data efficient than deep learning, it could simply replace deep learning and become the dominant paradigm. This would be a much better endgame position for humans to control and develop future advanced AIs.
| Path | Feasibility | Safety |
|---|---|---|
| Comprehensive AI Services | Very feasible | Very safe but unstable in the very long run |
| Liberation | Feasible | Unsafe but could enable a pivotal act that makes things stable in the long run |
| Guided Meditation | Very Hard | Fairly safe and could unlock a safer tech than deep learning which results in a better end-game position for humanity. |
I have tried Camille's in-person workshop in the past and was very happy with it. I highly recommend it. It helped me discover many unknown unknowns.
Deleted paragraph from the post, that might answer the question:
Surprisingly, the same study found that even if there were an escalation of warning shots that ended up killing 100k people or >$10 billion in damage (definition), skeptics would only update their estimate from 0.10% to 0.25% [1]: There is a lot of inertia, we are not even sure this kind of “strong” warning shot would happen, and I suspect this kind of big warning shot could happen beyond the point of no return because this type of warning shot requires autonomous replication and adaptation abilities in the wild.
- ^
It may be because they expect a strong public reaction. But even if there was a 10-year global pause, what would happen after the pause? This explanation does not convince me. Did the government prepare for the next covid?
Thanks for this comment, but I think this might be a bit overconfident.
Yes, I have no doubt that if humans implement some kind of defense, this will slow down ARA a lot. But:
"at the same rate" not necessarily. If we don't solve alignment and we implement a pause on AI development in labs, the ARA AI may still continue to develop. The real crux is how much time the ARA AI needs to evolve into something scary.
We don't learn much here. From my side, I think that superintelligence is not going to be neglected, and big labs are taking this seriously already. I’m still not clear on ARA.
This is not the central point. The central point is:
I’m pretty surprised by this. I’ve tried to google and not found anything.
Overall, I think this still deserves more research